Título alfa de todas las publicaciones de los usuarios. Utilizamos funciones de Google poco conocidas para encontrar cosas ocultas. ¿Qué oportunidades abre la nueva plataforma para los bloggers?
A finales de noviembre de 2016, el equipo de desarrollo de Telegram Messenger presentó un nuevo servicio de publicación online. Telégrafo es una herramienta especial que le permite crear textos voluminosos basados en el ligero lenguaje de marcado web Markdown. Usando esta plataforma, puedes publicar artículos en Internet con fotos, videos y otros elementos incrustados. Al mismo tiempo, no es necesario registrarse con datos personales, lo que permite mantener un completo anonimato.
¿Qué oportunidades abre la nueva plataforma para los bloggers?
Según los desarrolladores del servicio, el usuario tiene la posibilidad de presentar la información de la misma forma que lo hacen los medios tradicionales. Telegraph tiene todo lo que necesitas para esto:
 Para demostrar la versatilidad del producto, los desarrolladores publicaron una API en el dominio telegra.ph.
Para demostrar la versatilidad del producto, los desarrolladores publicaron una API en el dominio telegra.ph.
Externamente, el contenido de Telegraph no se diferencia de los materiales publicados en los recursos web de los medios habituales; sin embargo, el anonimato de la autoría y la visualización de artículos directamente en el Messenger abren oportunidades únicas para los bloggers modernos. Las publicaciones más interesantes creadas con el nuevo servicio se presentan en excelente formato.
Cómo trabajar con Telégrafo
Para utilizar esta herramienta, debe visitar www.telegra.ph. Al acceder a esta dirección, el usuario se encuentra con una página casi vacía con tres simples líneas: Título, Tu nombre, Tu historia.
- La línea Título está destinada a escribir el título del artículo, que, junto con la fecha de publicación, forma un enlace al contenido. Por ejemplo, el artículo “Cómo promocionar un sitio web entre los 10 primeros”, publicado el 5 de abril, tendrá el enlace: “http://telegra.ph/Kak-prodvinut-sajt-v-top-10-04- 05.”
 La interfaz de la herramienta de creación de artículos telegra.ph es muy sencilla
La interfaz de la herramienta de creación de artículos telegra.ph es muy sencilla - El elemento Su nombre es opcional. El autor puede indicar su nombre real, seudónimo, apodo, o dejar la línea completamente en blanco para que nadie pueda determinar su identidad. La posibilidad de publicar material permaneciendo de incógnito es bastante interesante. Pero la mayoría de los escritores están felices de indicar su autoría.
- Tu historia es un campo para crear el contenido principal. Esto también abre las posibilidades de formato de texto, que se discutieron anteriormente. El algoritmo para crear un artículo es muy sencillo e intuitivo, por lo que los usuarios no deberían tener dificultades para escribirlo.
Un enlace único le permite utilizar el material publicado no solo en Telegram, sino también en otros sitios. Sin embargo, el creador puede realizar cambios en el contenido en cualquier momento. Sin embargo, esta función sólo funciona si se guardan las cookies.
 Para gestionar fácilmente todos los artículos, utilice el bot.
Para gestionar fácilmente todos los artículos, utilice el bot. Para crear un artículo, se requiere un mínimo de acciones por parte del usuario. Sin embargo, esta facilidad ha reverso. Solo se pueden realizar ediciones adicionales en el mismo dispositivo y navegador en el que se publicó el texto por primera vez. Los desarrolladores previeron esta situación e crearon un bot especial para gestionar las publicaciones. Enumeremos su funcionalidad:
- Autorización en Telegraph desde tu cuenta de Telegram. Al crear una entrada de esta manera, puede iniciar sesión en cualquier otro dispositivo y tener acceso de edición. Cuando inicies sesión por primera vez en cada dispositivo, el robot te ofrecerá agregar todas las publicaciones creadas previamente a tu cuenta.
- Estadísticas de vistas de cualquier puesto de telégrafo. Esto tiene en cuenta todas las transiciones al artículo, no solo desde Telegram, sino también desde cualquier recurso externo. Puedes analizar no solo tus propias publicaciones, simplemente envía al bot el enlace que te interesa.
- Puede establecer un apodo permanente y un enlace de perfil para no tener que especificarlos cada vez.
Telegraph: ¿una amenaza real para los medios tradicionales?
Los mensajeros, que por naturaleza pertenecen al ámbito de los medios de comunicación, se están desarrollando a un ritmo rápido y se están transformando en plataformas convenientes para publicar información útil. La aparición de un servicio como Telegraph ha facilitado aún más la creación de una plataforma empresarial completa para atraer al usuario final. Muchas marcas ya están comprendiendo que este tipo de comunicación es cada vez más relevante.
Sin embargo, todavía es prematuro decir que la mensajería instantánea en general y Telegraph en particular crean competencia directa con los medios tradicionales. Los expertos definen este tipo de servicios como una herramienta adicional para generar contenidos en Internet, que pueden ser de gran ayuda para los medios de comunicación, pero que en esta fase de desarrollo no son capaces de absorberlos por completo.
 Los medios online desconfían de las plataformas competidoras
Los medios online desconfían de las plataformas competidoras Hackear en ayuda de google
Alejandro Antipov
El motor de búsqueda de Google (www.google.com) ofrece muchas opciones de búsqueda. Todas estas funciones son una herramienta de búsqueda invaluable para un usuario nuevo en Internet y, al mismo tiempo, un arma de invasión y destrucción aún más poderosa en manos de personas con malas intenciones, incluidos no solo piratas informáticos, sino también delincuentes no informáticos y Incluso terroristas.
(9475 visitas en 1 semana)
Denis Barankov
denisNOSPAMixi.ru
Atención:Este artículo no es una guía de acción. Este artículo fue escrito para ustedes, administradores de servidores WEB, para que pierdan la falsa sensación de que están seguros y finalmente comprendan lo insidioso de este método de obtener información y asuman la tarea de proteger su sitio.
Introducción
Por ejemplo, ¡encontré 1670 páginas en 0,14 segundos!
2. Ingresemos otra línea, por ejemplo:
inurl: "auth_user_file.txt"un poco menos, pero esto ya es suficiente para descargar y adivinar contraseñas de forma gratuita (usando el mismo John The Ripper). A continuación daré una serie de ejemplos más.
Por lo tanto, debe darse cuenta de que el motor de búsqueda de Google ha visitado la mayoría de los sitios de Internet y ha almacenado en caché la información contenida en ellos. Esta información almacenada en caché le permite obtener información sobre el sitio y el contenido del sitio sin conectarse directamente al sitio, solo profundizando en la información que está almacenada dentro de Google. Además, si la información del sitio ya no está disponible, es posible que la información del caché aún se conserve. Todo lo que necesitas para este método es conocer algunas palabras clave de Google. Esta técnica se llama Google Hacking.
La información sobre Google Hacking apareció por primera vez en la lista de correo de Bugtruck hace 3 años. En 2001, un estudiante francés planteó este tema. Aquí hay un enlace a esta carta http://www.cotse.com/mailing-lists/bugtraq/2001/Nov/0129.html. Proporciona los primeros ejemplos de este tipo de consultas:
1) Índice de /admin
2) Índice de /contraseña
3) Índice de /correo
4) Índice de / +banques +tipo de archivo:xls (para francia...)
5) Índice de / +contraseña
6) Índice de /contraseña.txt
Este tema causó sensación en la sección de lectura en inglés de Internet recientemente: después del artículo de Johnny Long, publicado el 7 de mayo de 2004. Para un estudio más completo sobre Google Hacking, le aconsejo que visite el sitio web de este autor http://johnny.ihackstuff.com. En este artículo solo quiero ponerte al día.
¿Quién puede usar esto?
- Los periodistas, los espías y todas aquellas personas a las que les gusta meterse en los asuntos ajenos pueden utilizar esto para buscar pruebas incriminatorias.
- Hackers que buscan objetivos adecuados para hackear.
Cómo funciona Google.
Para continuar la conversación, permítanme recordarles algunas de las palabras clave utilizadas en las consultas de Google.
Buscar usando el signo +
Google excluye de las búsquedas las palabras que considera sin importancia. Por ejemplo, palabras interrogativas, preposiciones y artículos en inglés: por ejemplo son, de, dónde. En ruso idioma de google Parece considerar todas las palabras importantes. Si una palabra se excluye de la búsqueda, Google escribe sobre ella. Para que Google comience a buscar páginas con estas palabras, debe agregar un signo + sin espacio antes de la palabra. Por ejemplo:
as + de base
Buscar usando el signo –
Si Google encuentra una gran cantidad de páginas de las cuales necesita excluir páginas con un tema determinado, puede obligar a Google a buscar solo páginas que no contengan determinadas palabras. Para hacer esto, debe indicar estas palabras colocando un signo delante de cada una, sin un espacio antes de la palabra. Por ejemplo:
pesca - vodka
Buscar usando ~
Es posible que desee buscar no sólo la palabra especificada, sino también sus sinónimos. Para hacer esto, anteponga la palabra con el símbolo ~.
Encontrar una frase exacta usando comillas dobles
Google busca en cada página todas las apariciones de las palabras que usted escribió en la cadena de consulta, y no le importa la posición relativa de las palabras, siempre y cuando todas las palabras especificadas estén en la página al mismo tiempo (esto es la acción predeterminada). Para encontrar la frase exacta, debes ponerla entre comillas. Por ejemplo:
"sujetalibros"
Para tener al menos una de las palabras especificadas, debe especificar explícitamente la operación lógica: OR. Por ejemplo:
seguridad del libro O protección
Además, puedes utilizar el signo * en la barra de búsqueda para indicar cualquier palabra y. para representar cualquier personaje.
Buscar palabras usando operadores adicionales
Hay operadores de búsqueda que se especifican en la cadena de búsqueda en el formato:
operador: término_búsqueda
Los espacios al lado de los dos puntos no son necesarios. Si inserta un espacio después de los dos puntos, verá un mensaje de error y, antes, Google los utilizará como una cadena de búsqueda normal.
Hay grupos de operadores de búsqueda adicionales: idiomas: indique en qué idioma desea ver el resultado, fecha: limite los resultados de los últimos tres, seis o 12 meses, ocurrencias: indique en qué parte del documento necesita buscar la línea: en todas partes, en el título, en la URL, dominios: busque en el sitio especificado o, por el contrario, exclúyalo de la búsqueda; búsqueda segura: bloquea los sitios que contienen el tipo de información especificado y los elimina de las páginas de resultados de búsqueda.
Sin embargo, algunos operadores no requieren un parámetro adicional, por ejemplo la solicitud " caché: www.google.com" se puede llamar como una cadena de búsqueda completa y, por el contrario, algunas palabras clave requieren una palabra de búsqueda, por ejemplo " sitio:www.google.com ayuda". A la luz de nuestro tema, veamos los siguientes operadores:
Operador |
Descripción |
Requiere parámetro adicional? |
buscar solo en el sitio especificado en search_term |
||
buscar solo en documentos con tipo search_term |
||
buscar páginas que contengan search_term en el título |
||
buscar páginas que contengan todas las palabras de términos de búsqueda en el título |
||
buscar páginas que contengan la palabra search_term en su dirección |
||
buscar páginas que contengan todas las palabras de términos de búsqueda en su dirección |
Operador sitio: limita la búsqueda solo al sitio especificado, y puede especificar no solo Nombre de dominio, pero también una dirección IP. Por ejemplo, ingrese:
Operador Tipo de archivo: Limita la búsqueda a un tipo de archivo específico. Por ejemplo:
A la fecha de publicación del artículo, Google puede buscar en 13 formatos de archivos diferentes:
- Formato de documento portátil de Adobe (pdf)
- Adobe PostScript (ps)
- Loto 1-2-3 (semana1, semana2, semana3, semana4, semana5, semana, semana, semana)
- Lotus WordPro (lwp)
- MacWrite (mW)
- Microsoft Excel (xls)
- Microsoft PowerPoint (ppt)
- Microsoft Word(doc)
- Microsoft Works (semanas, wps, wdb)
- Escritura de Microsoft (escritura)
- Formato de texto enriquecido (rtf)
- Shockwave Flash(swf)
- Texto (ans, txt)
Operador enlace: muestra todas las páginas que apuntan a la página especificada.
Probablemente siempre sea interesante ver cuántos lugares en Internet saben sobre ti. Intentemos:
Operador cache: muestra la versión del sitio en el caché de Google, cómo se veía cuando Google más reciente Visité esta página una vez. Tomemos cualquier sitio que cambie con frecuencia y miremos:
Operador título: busca la palabra especificada en el título de la página. Operador todo en título: es una extensión: busca todas las pocas palabras especificadas en el título de la página. Comparar:
título: vuelo a Marte
intitle:vuelo intitle:en intitle:marte
allintitle:vuelo a marte
Operador URL interna: obliga a Google a mostrar todas las páginas que contienen la cadena especificada en la URL. Operador allinurl: busca todas las palabras en una URL. Por ejemplo:
allinurl:ácido acid_stat_alerts.php
Este comando es especialmente útil para aquellos que no tienen SNORT - al menos pueden ver cómo funciona en un sistema real.
Métodos de piratería con Google
Entonces, descubrimos que usando una combinación de los operadores y palabras clave anteriores, cualquiera puede recopilar la información necesaria y buscar vulnerabilidades. Estas técnicas suelen denominarse Google Hacking.
Mapa del sitio
Puede utilizar el operador site: para enumerar todos los enlaces que Google ha encontrado en un sitio. Normalmente, las páginas creadas dinámicamente mediante scripts no se indexan mediante parámetros, por lo que algunos sitios utilizan filtros ISAPI para que los enlaces no tengan el formato /artículo.asp?num=10&dst=5, y con barras /artículo/abc/num/10/dst/5. Esto se hace para que el sitio sea indexado generalmente por los motores de búsqueda.
Intentemos:
sitio: www.whitehouse.gov casa blanca
Google cree que cada página de un sitio web contiene la palabra casa blanca. Esto es lo que usamos para obtener todas las páginas.
También existe una versión simplificada:
sitio: whitehouse.gov
Y la mejor parte es que los camaradas de whitehouse.gov ni siquiera sabían que mirábamos la estructura de su sitio e incluso miramos las páginas en caché que descargó Google. Esto se puede utilizar para estudiar la estructura de los sitios y ver el contenido, sin ser detectado por el momento.
Ver una lista de archivos en directorios
Los servidores WEB pueden mostrar listas de directorios de servidores en lugar de los habituales páginas HTML. Esto generalmente se hace para alentar a los usuarios a seleccionar y descargar ciertos archivos. Sin embargo, en muchos casos, los administradores no tienen intención de mostrar el contenido de un directorio. Esto ocurre debido a una configuración incorrecta del servidor o falta de pagina de inicio en el directorio. Como resultado, el hacker tiene la posibilidad de encontrar algo interesante en el directorio y utilizarlo para sus propios fines. Para encontrar todas estas páginas, basta con tener en cuenta que todas contienen las palabras: índice de. Pero dado que el índice de palabras de contiene no solo dichas páginas, debemos refinar la consulta y tener en cuenta las palabras clave en la página misma, por lo que consultas como:
intitle:index.del directorio principal
intitle:index.of nombre tamaño
Dado que la mayoría de los listados de directorios son intencionales, es posible que le resulte difícil encontrar listados fuera de lugar la primera vez. Pero al menos ya puedes utilizar listados para determinar la versión del servidor WEB, como se describe a continuación.
Obtención de la versión del servidor WEB.
Conocer la versión del servidor WEB siempre es útil antes de lanzar cualquier ataque de piratas informáticos. Nuevamente, gracias a Google, puedes obtener esta información sin conectarte a un servidor. Si observa detenidamente la lista del directorio, puede ver que allí se muestra el nombre del servidor WEB y su versión.
Apache1.3.29 - Servidor ProXad en trf296.free.fr Puerto 80
Un administrador experimentado puede cambiar esta información, pero esto suele ser cierto. Así, para obtener esta información basta con enviar una solicitud:
intitle:index.of server.at
Para obtener información para un servidor específico, aclaramos la solicitud:
intitle:index.of server.en el sitio:ibm.com
O viceversa, buscamos servidores que ejecuten una versión específica del servidor:
intitle:index.of Servidor Apache/2.0.40 en
Un pirata informático puede utilizar esta técnica para encontrar una víctima. Si, por ejemplo, tiene un exploit para una determinada versión del servidor WEB, puede encontrarlo y probar el exploit existente.
También puede obtener la versión del servidor viendo las páginas que se instalan de forma predeterminada al instalar la última versión del servidor WEB. Por ejemplo, para ver la página de prueba de Apache 1.2.6, simplemente escriba
intitle:Página.de.prueba.para.Apache, ¡funcionó!
Es más, algunos SO Durante la instalación, instalan e inician inmediatamente el servidor WEB. Sin embargo, algunos usuarios ni siquiera son conscientes de ello. Naturalmente, si ve que alguien no ha eliminado la página predeterminada, entonces es lógico suponer que la computadora no ha sido sometida a ninguna personalización y probablemente sea vulnerable a ataques.
Intente buscar páginas de IIS 5.0
allintitle:Bienvenido a Servicios de Internet de Windows 2000
En el caso de IIS, puede determinar no sólo la versión del servidor, sino también versión de Windows y paquete de servicio.
Otra forma de determinar la versión del servidor WEB es buscar manuales (páginas de ayuda) y ejemplos que puedan estar instalados en el sitio de forma predeterminada. Los piratas informáticos han encontrado bastantes formas de utilizar estos componentes para obtener acceso privilegiado a un sitio. Por eso es necesario retirar estos componentes en el sitio de producción. Sin olvidar que la presencia de estos componentes se puede aprovechar para obtener información sobre el tipo de servidor y su versión. Por ejemplo, busquemos el manual de Apache:
inurl: módulos de directivas manuales de apache
Usando Google como escáner CGI.
El escáner CGI o escáner WEB es una utilidad para buscar scripts y programas vulnerables en el servidor de la víctima. Estas utilidades deben saber qué buscar, para ello cuentan con una lista completa de archivos vulnerables, por ejemplo:
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/lista de correo.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgi
Podemos encontrar cada uno de estos archivos usando Google, usando adicionalmente las palabras index of o inurl con el nombre del archivo en la barra de búsqueda: podemos encontrar sitios con scripts vulnerables, por ejemplo:
allinurl:/random_banner/index.cgi
Utilizando conocimientos adicionales, un pirata informático puede explotar la vulnerabilidad de un script y utilizar esta vulnerabilidad para obligar al script a emitir cualquier archivo almacenado en el servidor. Por ejemplo, un archivo de contraseña.
Cómo protegerse del hackeo de Google.
1. No publique datos importantes en el servidor WEB.
Incluso si publicó los datos temporalmente, es posible que se olvide de ellos o que alguien tenga tiempo de encontrarlos y tomarlos antes de que los borre. No hagas eso. Hay muchas otras formas de transferir datos que los protegen del robo.
2. Revisa tu sitio.
Utilice los métodos descritos para investigar su sitio. Revise su sitio periódicamente para ver los nuevos métodos que aparecen en el sitio http://johnny.ihackstuff.com. Recuerda que si quieres automatizar tus acciones, necesitas obtener un permiso especial de Google. Si lees atentamente http://www.google.com/terms_of_service.html, luego verá la frase: No puede enviar consultas automáticas de ningún tipo al sistema de Google sin el permiso previo expreso de Google.
3. Es posible que no necesite que Google indexe su sitio o parte de él.
Google le permite eliminar un enlace a su sitio o parte de él de su base de datos, así como eliminar páginas del caché. Además, puede prohibir la búsqueda de imágenes en su sitio, prohibir que se muestren fragmentos cortos de páginas en los resultados de búsqueda. Todas las posibilidades para eliminar un sitio se describen en la página. http://www.google.com/remove.html. Para hacer esto, debe confirmar que es realmente el propietario de este sitio o insertar etiquetas en la página o
4. Utilice robots.txt
Se sabe que los motores de búsqueda miran el archivo robots.txt ubicado en la raíz del sitio y no indexan aquellas partes que están marcadas con la palabra Rechazar. Puede utilizar esto para evitar que se indexe parte del sitio. Por ejemplo, para evitar que se indexe todo el sitio, cree un archivo robots.txt que contenga dos líneas:
Agente de usuario: *
No permitir: /
¿Qué más pasa?
Para que la vida no te parezca miel, diré finalmente que existen sitios que monitorean a aquellas personas que, utilizando los métodos descritos anteriormente, buscan agujeros en scripts y servidores WEB. Un ejemplo de una página de este tipo es
Solicitud.
Un poco dulce. Pruebe algunos de los siguientes usted mismo:
1. #mysql dump filetype:sql - busca volcados de bases de datos datos mysql
2. Informe resumido de vulnerabilidades del host: le mostrará qué vulnerabilidades han encontrado otras personas.
3. phpMyAdmin ejecutándose en inurl:main.php: esto forzará el cierre del control a través del panel phpmyadmin
4. no para distribución confidencial
5. Solicitar detalles Variables del servidor del árbol de control
6. Ejecutar en modo infantil
7. Este informe fue generado por WebLog.
8. título: índice.de cgiirc.config
9. tipo de archivo:conf inurl:firewall -intitle:cvs – ¿quizás alguien necesite archivos de configuración del firewall? :)
10. intitle:index.of Finances.xls - hmm....
11. intitle: Índice de chats dbconvert.exe - registros de chat icq
12.intext:Análisis de tráfico de Tobias Oetiker
13. intitle: Estadísticas de uso generadas por Webalizer
14. intitle:estadísticas de estadísticas web avanzadas
15. intitle:index.of ws_ftp.ini – configuración ws ftp
16. inurl:ipsec.secrets contiene secretos compartidos - clave secreta - buen hallazgo
17. inurl:main.php Bienvenido a phpMyAdmin
18. inurl:información del servidor Información del servidor Apache
19. sitio: calificaciones de administrador educativo
20. ORA-00921: final inesperado del comando SQL: obtención de rutas
21. título: índice.de trillian.ini
22. intitle: Índice de pwd.db
23.intitle:índice.de personas.lst
24. título: índice.de.contraseña.maestra
25.inurl:lista de contraseñas.txt
26. intitle: Índice de .mysql_history
27. intitle: índice de intext: globals.inc
28. título: índice.de administradores.pwd
29. intitle:Index.of etc sombra
30.intitle:index.ofsecring.pgp
31. inurl:config.php dbuname dbpass
32. inurl: realizar tipo de archivo: ini
Centro de formación "Informzashchita" http://www.itsecurity.ru: un centro especializado líder en el campo de la formación seguridad de información(Licencia del Comité de Educación de Moscú No. 015470, acreditación estatal No. 004251). El único centro de formación autorizado para empresas seguridad de Internet Systems y Clearswift en Rusia y los países de la CEI. Centro de formación autorizado por Microsoft (especialización en Seguridad). Los programas de formación se coordinan con la Comisión Técnica Estatal de Rusia, el FSB (FAPSI). Certificados de formación y documentos estatales sobre formación avanzada.
SoftKey es un servicio único para compradores, desarrolladores, distribuidores y socios afiliados. Además, éste es uno de los mejores tiendas en línea Software en Rusia, Ucrania, Kazajstán, que ofrece a los clientes una amplia gama, muchos métodos de pago, procesamiento de pedidos rápido (a menudo instantáneo), seguimiento del proceso de pedido en una sección personal, varios descuentos de la tienda y fabricantes de software.
Cómo buscar correctamente usando google.com
Probablemente todo el mundo sepa cómo utilizar esto. buscador, como Google =) Pero no todo el mundo sabe que si redacta correctamente una consulta de búsqueda utilizando construcciones especiales, puede lograr los resultados que busca de forma mucho más eficiente y rápida =) En este artículo intentaré mostrar qué y cómo debes hacer para buscar correctamente
Google admite varios operadores de búsqueda avanzada que tienen un significado especial al realizar búsquedas en google.com. Normalmente, estas declaraciones cambian la búsqueda o incluso le dicen a Google que realice tipos de búsquedas completamente diferentes. Por ejemplo, el diseño enlace: es un operador especial, y la solicitud enlace: www.google.com no le dará una búsqueda normal, sino que encontrará todas las páginas web que tengan enlaces a google.com.
tipos de solicitud alternativos
cache: Si incluye otras palabras en su consulta, Google resaltará esas palabras incluidas dentro del documento almacenado en caché.
Por ejemplo, caché: www.sitio web mostrará el contenido almacenado en caché con la palabra "web" resaltada.
enlace: La consulta de búsqueda anterior mostrará páginas web que contienen enlaces a la consulta especificada.
Por ejemplo: enlace: www.sitio mostrará todas las páginas que tengan un enlace a http://www.site
relacionado: Muestra páginas web que están "relacionadas" con la página web especificada.
Por ejemplo, relacionado: www.google.com enumerará páginas web que son similares a la página de inicio de Google.
información: Información de consulta: presentará parte de la información que Google tiene sobre la página web que está solicitando.
Por ejemplo, información:sitio web mostrará información sobre nuestro foro =) (Armada - Foro de webmasters para adultos).
Otras solicitudes de información
definir: La consulta definir: proporcionará una definición de las palabras que ingrese después, recopiladas de varias fuentes en línea. La definición será para toda la frase ingresada (es decir, incluirá todas las palabras en la consulta exacta).
cepo: Si inicia una consulta con acciones: Google procesará el resto de los términos de la consulta como símbolos de acciones y vinculará a una página que muestra información preparada para estos símbolos.
Por ejemplo, acciones: Intel Google mostrará información sobre Intel y Yahoo. (Tenga en cuenta que debe escribir los símbolos de las noticias de última hora, no el nombre de la empresa)
Modificadores de consulta
sitio: Si incluye sitio: en su consulta, Google limitará los resultados a aquellos sitios web que encuentre en ese dominio.
También puede buscar por zonas individuales, como ru, org, com, etc ( sitio: com sitio: ru)
todo en título: Si ejecuta una consulta con allintitle:, Google limitará los resultados a todas las palabras de consulta en el título.
Por ejemplo, allintitle: búsqueda de google devolverá todas las páginas de Google mediante búsqueda, como imágenes, blog, etc.
título: Si incluye intitle: en su consulta, Google limitará los resultados a documentos que contengan esa palabra en el título.
Por ejemplo, título:Negocios
allinurl: Si ejecuta una consulta con allinurl: Google limitará los resultados a todas las palabras de consulta en la URL.
Por ejemplo, allinurl: búsqueda de google Devolverá documentos con google y buscará en el título. Además, como opción, puede separar las palabras con una barra (/), luego las palabras en ambos lados de la barra se buscarán dentro de la misma página: Ejemplo allinurl: foo/bar
URL interna: Si incluye inurl: en su consulta, Google limitará los resultados a documentos que contengan esa palabra en la URL.
Por ejemplo, Animación inurl:sitio
en el texto: busca solo la palabra especificada en el texto de la página, ignorando el título y los textos de los enlaces, y otras cosas no relacionadas con... También existe un derivado de este modificador: todo el texto: aquellos. Además, todas las palabras de la consulta se buscarán sólo en el texto, lo que también puede ser importante, ignorando las palabras de uso frecuente en los enlaces.
Por ejemplo, intexto:foro
rango de fechas: búsquedas en un período de tiempo (rango de fechas: 2452389-2452389), las fechas de las horas se indican en formato juliano.
Bueno, y todo tipo de ejemplos interesantes de consultas.
Ejemplos de redacción de consultas para Google. Para spammers
Inurl:control.guest?a=signo
Sitio:books.dreambook.com “URL de la página de inicio” “Firmar mi” inurl:firmar
Sitio: www.freegb.net Página de inicio
Inurl:sign.asp “Recuento de caracteres”
“Mensaje:” inurl:sign.cfm “Remitente:”
Inurl:register.php “Registro de usuario” “Sitio web”
Inurl:edu/guestbook “Firma el libro de visitas”
Inurl:publicar “Publicar comentario” “URL”
Inurl:/archives/ “Comentarios:” “¿Recuerdas la información?”
“Guión y libro de visitas creado por:” “URL:” “Comentarios:”
Inurl:?acción=añadir “phpBook” “URL”
Título: "Enviar nueva historia"
Revistas
URL interna: www.livejournal.com/users/ mode=reply
Inurl greatjournal.com/mode=respuesta
URL interna: fastbb.ru/re.pl?
Inurl:fastbb.ru /re.pl? "Libro de visitas"
Blogs
Inurl:blogger.com/comment.g?”postID””anónimo”
Inurl:typepad.com/ “Publicar un comentario” “¿Recuerdas información personal?”
Inurl:greatestjournal.com/community/ “Publicar comentario” “direcciones de carteles anónimos”
“Comentario de publicación” “direcciones de anunciantes anónimos” -
Título:"Publicar comentario"
Inurl:pirillo.com “Publicar comentario”
Foros
Inurl:gate.html?”nombre=Foros” “modo=respuesta”
Inurl:”foro/posting.php?mode=respuesta”
URL interna: "mes.php?"
URL interna:”miembros.html”
¿Inurl:foro/memberlist.php?
La función Historias, o “Historias” en la localización rusa, te permite crear fotos y videos de 10 segundos con superposición de texto, emoji y notas escritas a mano. Función clave Lo que pasa con este tipo de publicaciones es que, a diferencia de las publicaciones habituales en tu feed, no duran para siempre y se eliminan exactamente después de 24 horas.
¿Por qué es necesario?
La descripción oficial de Instagram dice que nueva caracteristica realmente no es necesario para el intercambio información importante sobre la vida cotidiana.
Cómo usarlo
En esencia, la innovación es muy similar y funciona aproximadamente igual, pero con pequeñas diferencias. A pesar de que las oportunidades Historias de Instagram no tantos y todos son muy sencillos, no todos los usuarios pueden descifrarlos de inmediato.
Ver historias
Todas las historias disponibles se muestran en la parte superior del feed en forma de círculos con avatares de usuarios y se ocultan al desplazarse. Nuevas historias aparecen a medida que se publican y un día después desaparecen sin dejar rastro. En este caso, las historias no se ordenan en orden cronológico, sino por el número de ciclos de reproducción y comentarios.

Para verlo, sólo tienes que tocar el círculo. Se abrirá una foto o un vídeo y se mostrará durante 10 segundos. Tocar y mantener pausa el video.
En la parte superior, junto al nombre de usuario, se muestra la hora de publicación. Si las personas que sigues tienen otras historias, las siguientes se mostrarán inmediatamente después de la primera. Puedes cambiar entre ellos deslizando el dedo hacia la izquierda y hacia la derecha.


Las historias que ya has visto no desaparecen del menú, sino que aparecen atenuadas. Se pueden volver a abrir hasta que se eliminen después de un día.
Puede comentar historias solo usando mensajes que se envían a Direct y que son visibles solo para el autor y no para todos los suscriptores. Se desconoce si se trata de un error o de una característica.
Creando historias
Al hacer clic en el signo más en la parte superior del feed y deslizar el dedo desde el borde de la pantalla hacia la derecha, se abre el menú para grabar una nueva historia. Aquí todo es simple: toca el botón de grabación, obtenemos una foto, la mantenemos presionada y grabamos un video.
Disparar o cargar


Puede cambiar las cámaras delantera y trasera o encender el flash. También es fácil seleccionar un archivo multimedia entre los que se tomaron en las últimas 24 horas: esto se hace deslizando el dedo hacia abajo. Todas las fotos de la galería van aquí, incluidos los time-lapses y los boomerangs de marca.
Tratamiento
Cuando la foto o el vídeo esté listo, podrás publicarlo después de procesarlo. Tanto para fotos como para vídeos, las herramientas son las mismas: filtros, texto y emoji, dibujos.


Los filtros se cambian en círculo con simples deslizamientos desde el borde de la pantalla. Hay seis en total, incluido un degradado de arco iris como en el ícono de Instagram.
El texto agregado se puede ampliar, reducir o mover por la foto. Pero, lamentablemente, no puedes dejar más de un comentario. Los emoji también se insertan a través del texto, por lo que si quieres cubrir tu cara con un emoticón, debes elegir.


El dibujo tiene un poco más de opciones. Tenemos a nuestra disposición una paleta y tres pinceles: normal, rotulador y con trazo “neón”. Puedes dibujar con todos a la vez y un mal trazo se puede deshacer.
¿Estas satisfecho con el resultado? Haga clic en el botón de marca de verificación y su video estará disponible para los suscriptores. Se puede guardar en la galería tanto antes como después.
Configuración de privacidad, estadísticas.


La pantalla de configuración y estadísticas se abre deslizando hacia arriba mientras se ve una historia. Desde aquí, la historia se puede guardar en la galería, eliminar o publicar en el feed principal, convirtiéndola en una publicación normal. La lista de espectadores se muestra a continuación. Puedes ocultar la historia a cualquiera de ellos haciendo clic en la cruz al lado del nombre.


La configuración, que está oculta detrás del ícono de ajustes, le permite elegir quién puede responder a sus historias y ocultar la historia a ciertos suscriptores. En este caso, la configuración de privacidad se recuerda y se aplica a todas las publicaciones posteriores.
Cómo vivir con eso
Bien. Sí, muchos se mostraron hostiles a las Historias debido a la similitud con Snapchat y los problemas no resueltos de Instagram, en los que los desarrolladores deberían centrarse. Pero creo que la innovación es útil.
El problema de un feed desordenado, cuando tienes que dejar de seguir a amigos que publican literalmente cada paso que dan, existe desde hace mucho tiempo y nunca se ha inventado una solución clara. Las historias pueden considerarse el primer paso hacia esto. Con el tiempo, las personas deberían acostumbrarse a la cultura de comportamiento que ofrece y comenzar a publicar solo contenido realmente importante y digno de mención en su feed. Todo lo demás debería ir a Historias. ¿Es cierto?
Obtener datos privados no siempre significa piratear; a veces se publican en Acceso público. Conocimiento configuración de google y un poco de ingenio le permitirá encontrar muchas cosas interesantes, desde números de tarjetas de crédito hasta documentos del FBI.
ADVERTENCIA
Toda la información se proporciona únicamente con fines informativos. Ni los editores ni el autor son responsables de ningún posible daño causado por los materiales de este artículo.Hoy en día, todo está conectado a Internet, sin preocuparse por restringir el acceso. Por tanto, muchos datos privados se convierten en presa de los motores de búsqueda. Los robots Spider ya no se limitan a las páginas web, sino que indexan todo el contenido disponible en Internet y añaden constantemente información no pública a sus bases de datos. Descubrir estos secretos es fácil; sólo necesitas saber cómo preguntar sobre ellos.
buscando archivos
En manos capaces, Google encontrará rápidamente todo lo que no se encuentra en Internet, por ejemplo, información personal y archivos para uso oficial. A menudo están escondidos como una llave debajo de una alfombra: no existen restricciones de acceso reales, los datos simplemente se encuentran en la parte posterior del sitio, a donde no conducen enlaces. La interfaz web estándar de Google sólo proporciona configuraciones básicas de búsqueda avanzada, pero incluso éstas serán suficientes.
Puede limitar su búsqueda en Google a un tipo específico de archivo utilizando dos operadores: tipo de archivo y ext. El primero especifica el formato que el motor de búsqueda determinó a partir del título del archivo, el segundo especifica la extensión del archivo, independientemente de su contenido interno. Al buscar en ambos casos, solo necesita especificar la extensión. Inicialmente, el operador ext era conveniente de usar en los casos en que el archivo no tenía características de formato específicas (por ejemplo, para buscar archivos de configuración ini y cfg, que podían contener cualquier cosa). Ahora los algoritmos de Google han cambiado y no hay diferencias visibles entre los operadores; en la mayoría de los casos, los resultados son los mismos.

Filtrar los resultados
De forma predeterminada, Google busca palabras y, en general, cualquier carácter ingresado en todos los archivos de las páginas indexadas. Puedes limitar tu búsqueda por dominio nivel superior, un sitio específico o en la ubicación de la secuencia deseada en los propios archivos. Para las dos primeras opciones, utilice el operador del sitio, seguido del nombre del dominio o sitio seleccionado. En el tercer caso, todo un conjunto de operadores le permite buscar información en campos de servicio y metadatos. Por ejemplo, allinurl encontrará el indicado en el cuerpo de los enlaces, allinanchor - en el texto equipado con la etiqueta , allintitle - en los títulos de las páginas, allintext - en el cuerpo de las páginas.
Para cada operador existe una versión ligera con un nombre más corto (sin el prefijo todos). La diferencia es que allinurl encontrará enlaces con todas las palabras, e inurl solo encontrará enlaces con la primera de ellas. La segunda palabra y las siguientes de la consulta pueden aparecer en cualquier lugar de las páginas web. El operador inurl también se diferencia de otro operador con un significado similar: el sitio. El primero también le permite encontrar cualquier secuencia de caracteres en un enlace al documento buscado (por ejemplo, /cgi-bin/), que se usa ampliamente para encontrar componentes con vulnerabilidades conocidas.
Probémoslo en la práctica. Tomamos el filtro allintext y hacemos que la solicitud produzca una lista de números y códigos de verificación de tarjetas de crédito que caducarán solo en dos años (o cuando sus dueños se cansen de alimentar a todos).
Allintext: fecha de caducidad del número de tarjeta /2017 cvv 
Cuando lees en las noticias que un joven hacker “hackeó los servidores” del Pentágono o de la NASA, robando información clasificada, en la mayoría de los casos estamos hablando de una técnica básica de uso de Google. Supongamos que estamos interesados en una lista de empleados de la NASA y su información de contacto. Seguramente dicha lista está disponible en formato electrónico. Por comodidad o por descuido, también podrá estar en la propia página web de la organización. Es lógico que en este caso no existan enlaces al mismo, ya que está destinado a uso interno. ¿Qué palabras puede haber en un archivo así? Como mínimo: el campo "dirección". Probar todas estas suposiciones es fácil.

Inurl:nasa.gov tipo de archivo:xlsx "dirección"

Usamos la burocracia
Hallazgos como este son un buen toque. Una captura verdaderamente sólida la proporciona un conocimiento más detallado de los operadores de Google para webmasters, de la propia Red y de las peculiaridades de la estructura de lo que se busca. Conociendo los detalles, puedes filtrar fácilmente los resultados y refinar las propiedades de los archivos necesarios para obtener datos realmente valiosos en el resto. Es curioso que la burocracia venga al rescate aquí. Produce formulaciones estándar que son convenientes para buscar información secreta filtrada accidentalmente a Internet.
Por ejemplo, el sello de declaración de distribución, requerido por el Departamento de Defensa de EE. UU., significa restricciones estandarizadas sobre la distribución de un documento. La letra A denota comunicados públicos en los que no hay nada secreto; B - destinado únicamente para uso interno, C - estrictamente confidencial, y así sucesivamente hasta F. Se destaca por separado la letra X, que marca información particularmente valiosa que representa un secreto de estado del más alto nivel. Dejemos que quienes deben hacer esto de turno busquen dichos documentos, y nos limitaremos a los archivos con la letra C. Según la directiva DoDI 5230.24, esta marca se asigna a los documentos que contienen una descripción de tecnologías críticas que están bajo control de exportación. . Puede encontrar información tan cuidadosamente protegida en sitios con el dominio de nivel superior .mil, asignado al ejército de EE. UU.
"DECLARACIÓN DE DISTRIBUCIÓN C" inurl:navy.mil 
Es muy conveniente que el dominio .mil contenga únicamente sitios del Departamento de Defensa de EE. UU. y sus organizaciones contratadas. Los resultados de búsqueda con restricción de dominio son excepcionalmente claros y los títulos hablan por sí solos. Buscar secretos rusos de esta manera es prácticamente inútil: el caos reina en los dominios.ru y.rf, y los nombres de muchos sistemas de armas suenan a botánicos (PP "Kiparis", armas autopropulsadas "Akatsia") o incluso fabulosos ( TOS “Buratino”).

Al estudiar detenidamente cualquier documento de un sitio en el dominio .mil, podrá ver otros marcadores para refinar su búsqueda. Por ejemplo, una referencia a las restricciones a la exportación “Sec 2751”, que también resulta conveniente para buscar información técnica interesante. De vez en cuando se elimina de los sitios oficiales donde alguna vez apareció, por lo que si no puede seguir un enlace interesante en los resultados de búsqueda, use el caché de Google (operador de caché) o el sitio de Internet Archive.
Subiendo a las nubes
Además de los documentos gubernamentales desclasificados accidentalmente, ocasionalmente aparecen en el caché de Google enlaces a archivos personales de Dropbox y otros servicios de almacenamiento de datos que crean enlaces "privados" a datos publicados públicamente. Es aún peor con los servicios alternativos y caseros. Por ejemplo, la siguiente consulta busca datos de todos los clientes de Verizon que tienen un servidor FTP instalado y utilizan activamente su enrutador.
Allinurl:ftp://verizon.net
Ahora hay más de cuarenta mil personas inteligentes, y en la primavera de 2015 había muchas más. En lugar de Verizon.net, puedes sustituir el nombre de cualquier proveedor conocido, y cuanto más famoso sea, mayor será la captura. A través del servidor FTP integrado, puede ver archivos en un dispositivo de almacenamiento externo conectado al enrutador. Por lo general, se trata de un NAS para trabajo remoto, una nube personal o algún tipo de descarga de archivos de igual a igual. Todos los contenidos de dichos medios están indexados por Google y otros motores de búsqueda, por lo que puede acceder a los archivos almacenados en unidades externas a través de un enlace directo.

Mirando las configuraciones
Antes de la migración generalizada a la nube, los servidores FTP simples gobernaban como almacenamiento remoto, que también presentaban muchas vulnerabilidades. Muchos de ellos siguen siendo relevantes hoy. Por ejemplo, el popular programa WS_FTP Professional almacena datos de configuración, cuentas de usuario y contraseñas en el archivo ws_ftp.ini. Es fácil de encontrar y leer, ya que todos los registros se guardan en formato de texto y las contraseñas se cifran con el algoritmo Triple DES después de una mínima ofuscación. En la mayoría de las versiones, basta con descartar el primer byte.

Es fácil descifrar dichas contraseñas utilizando la utilidad WS_FTP Password Decryptor o un servicio web gratuito.

Cuando se habla de piratear un sitio web arbitrario, normalmente se refiere a obtener una contraseña a partir de registros y copias de seguridad de archivos de configuración de CMS o aplicaciones de comercio electrónico. si los conoces estructura típica, puede especificar fácilmente palabras clave. Líneas como las que se encuentran en ws_ftp.ini son extremadamente comunes. Por ejemplo, en Drupal y PrestaShop siempre hay un identificador de usuario (UID) y su correspondiente contraseña (pwd), y toda la información se almacena en archivos con extensión .inc. Puedes buscarlos de la siguiente manera:
"pwd=" "UID=" text:inc.
Revelar contraseñas DBMS
En los archivos de configuración de servidores SQL, nombres y direcciones Correo electrónico los usuarios se almacenan en texto claro y, en lugar de contraseñas, se registran sus hashes MD5. Estrictamente hablando, es imposible descifrarlos, pero se puede encontrar una coincidencia entre los pares de contraseña hash conocidos.

Todavía hay DBMS que ni siquiera utilizan hash de contraseñas. Los archivos de configuración de cualquiera de ellos se pueden visualizar simplemente en el navegador.
Intexto: DB_PASSWORD tipo de archivo: env 
Desde que apareció en servidores windows El lugar de los archivos de configuración fue ocupado parcialmente por el registro. Puede buscar entre sus ramas exactamente de la misma manera, utilizando reg como tipo de archivo. Por ejemplo, así:
Tipo de archivo: reg HKEY_CURRENT_USER "Contraseña"= 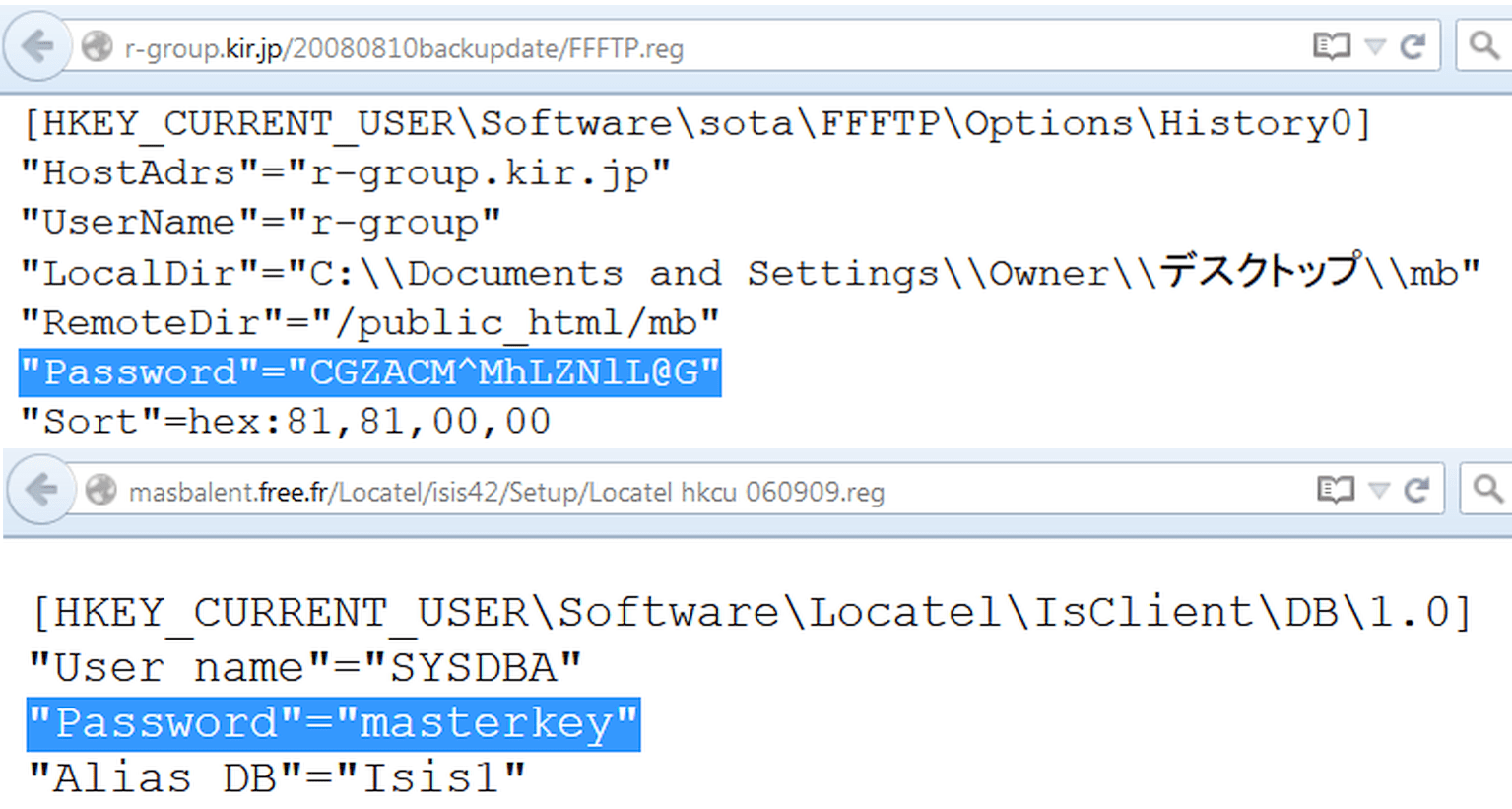
No olvidemos lo obvio
A veces es posible acceder a información clasificada utilizando datos que se abrieron accidentalmente y llamaron la atención de Google. Opción perfecta- busque una lista de contraseñas en algún formato común. Almacenar información de la cuenta en Archivo de texto, Documento de Word o una hoja de cálculo de Excel sólo la pueden hacer personas desesperadas, pero siempre hay suficientes.
Tipo de archivo:xls inurl:contraseña 
Por un lado, existen muchos medios para prevenir este tipo de incidentes. Es necesario especificar derechos de acceso adecuados en htaccess, parchear el CMS, no utilizar scripts para zurdos y cerrar otros agujeros. También hay un archivo con una lista de excepciones de robots.txt que prohíbe a los motores de búsqueda indexar los archivos y directorios especificados en él. Por otro lado, si la estructura de robots.txt en algún servidor difiere de la estándar, inmediatamente queda claro lo que están tratando de ocultar en él.

La lista de directorios y archivos de cualquier sitio está precedida por el índice estándar de. Dado que para fines de servicio debe aparecer en el título, tiene sentido limitar su búsqueda al operador del título. Hay cosas interesantes en los directorios /admin/, /personal/, /etc/ e incluso /secret/.

Estén atentos a las actualizaciones
La relevancia es extremadamente importante aquí: las vulnerabilidades antiguas se cierran muy lentamente, pero Google y sus resultados de búsqueda cambian constantemente. Incluso existe una diferencia entre un filtro de “último segundo” (&tbs=qdr:s al final de la URL de solicitud) y un filtro de “tiempo real” (&tbs=qdr:1).
Intervalo de fecha y hora última actualización Google también indica el archivo de forma implícita. A través de la interfaz gráfica web, puede seleccionar uno de los períodos estándar (hora, día, semana, etc.) o establecer un rango de fechas, pero este método no es adecuado para la automatización.
Por el aspecto de la barra de direcciones, solo puedes adivinar una forma de limitar la salida de resultados usando la construcción &tbs=qdr:. La letra y después establece el límite de un año (&tbs=qdr:y), m muestra los resultados del último mes, w - de la semana, d - del último día, h - de la última hora, n - por el minuto, y s - por dame un segundo. Los resultados más recientes que acaba de dar a conocer Google se encuentran utilizando el filtro &tbs=qdr:1 .
Si necesita escribir un script inteligente, será útil saber que el rango de fechas se establece en Google en formato juliano mediante el operador de rango de fechas. Por ejemplo, así es como puedes encontrar una lista. Documentos PDF con la palabra confidencial, subido del 1 de enero al 1 de julio de 2015.
Tipo de archivo confidencial: pdf rango de fechas: 2457024-2457205
El rango se indica en formato de fecha juliana sin tener en cuenta la parte fraccionaria. Traducirlos manualmente del calendario gregoriano es un inconveniente. Es más fácil utilizar un conversor de fechas.
Orientar y filtrar de nuevo
Además de especificar operadores adicionales en consulta de busqueda se pueden enviar directamente en el cuerpo del enlace. Por ejemplo, la especificación filetype:pdf corresponde a la construcción as_filetype=pdf . Esto hace conveniente preguntar cualquier aclaración. Digamos que la salida de resultados solo de la República de Honduras se especifica agregando la construcción cr=paísHN a la URL de búsqueda, y solo de la ciudad de Bobruisk - gcs=Bobruisk. Puede encontrar una lista completa en la sección de desarrolladores.
Las herramientas de automatización de Google están diseñadas para hacer la vida más fácil, pero a menudo añaden problemas. Por ejemplo, la ciudad del usuario está determinada por la IP del usuario a través de WHOIS. Basándose en esta información, Google no sólo equilibra la carga entre servidores, sino que también cambia los resultados de búsqueda. Dependiendo de la región, para la misma solicitud, aparecerán diferentes resultados en la primera página y algunos de ellos pueden estar completamente ocultos. El código de dos letras después de la directiva gl=country te ayudará a sentirte cosmopolita y a buscar información de cualquier país. Por ejemplo, el código de Holanda es NL, pero el Vaticano y Corea del Norte no tienen código propio en Google.
A menudo, los resultados de búsqueda terminan saturados incluso después de utilizar varios filtros avanzados. En este caso, es fácil aclarar la solicitud agregándole varias palabras de excepción (se coloca un signo menos delante de cada una de ellas). Por ejemplo, banca, nombres y tutorial se suelen utilizar con la palabra Personal. Por lo tanto, los resultados de búsqueda más limpios no se mostrarán mediante un ejemplo de consulta de libro de texto, sino mediante uno refinado:
Título:"Índice de /Personal/" -nombres -tutorial -banca
Un último ejemplo
Un hacker sofisticado se distingue por el hecho de que él mismo se proporciona todo lo que necesita. Por ejemplo, una VPN es algo cómodo, pero caro o temporal y con restricciones. Registrarse para obtener una suscripción es demasiado costoso. Es bueno que existan suscripciones grupales y con la ayuda de Google es fácil formar parte de un grupo. Para hacer esto, simplemente busque el archivo de configuración de Cisco VPN, que tiene una extensión PCF bastante no estándar y una ruta reconocible: Archivos de programa\Cisco Systems\VPN Client\Profiles. Una petición y te unirás, por ejemplo, al amable equipo de la Universidad de Bonn.
Tipo de archivo: pcf vpn OR Grupo 
INFORMACIÓN
Google encuentra archivos de configuración de contraseñas, pero muchos de ellos están cifrados o reemplazados con hashes. Si ve cadenas de longitud fija, busque inmediatamente un servicio de descifrado.Las contraseñas se almacenan cifradas, pero Maurice Massard ya ha escrito un programa para descifrarlas y lo proporciona de forma gratuita a través de thecampusgeeks.com.
Google hace cientos de cosas diferentes tipos Ataques y pruebas de penetración. Hay muchas opciones que afectan a programas populares, formatos de bases de datos importantes, numerosas vulnerabilidades de PHP, nubes, etc. Saber exactamente lo que está buscando hará que sea mucho más fácil encontrar la información que necesita (especialmente la información que no pretendía hacer pública). Shodan no es el único que se alimenta de ideas interesantes, ¡sino todas las bases de datos de recursos de red indexados!



