Alpha intitle all user publications. We use little-known Google features to find hidden things. What opportunities does the new platform open for bloggers?
At the end of November 2016, the Telegram messenger development team introduced a new service for online publishing. Telegraph is a special tool that allows you to create voluminous texts based on the lightweight web markup language Markdown. Using this platform, you can publish articles on the Internet with photos, videos and other embedded elements. At the same time, no registration with personal data is required, which makes it possible to maintain complete anonymity.
What opportunities does the new platform open for bloggers?
According to the developers of the service, the user has the opportunity to present information in the same way as traditional media do. Telegraph has everything you need for this:
 To demonstrate the versatility of the product, the developers published an API on the telegra.ph domain
To demonstrate the versatility of the product, the developers published an API on the telegra.ph domain
Externally, Telegraph content is no different from materials posted on the web resources of ordinary media, however, the anonymity of authorship and viewing articles directly in the messenger open up unique opportunities for modern bloggers. The most interesting publications created using the new service are presented in excellent form.
How to work with Telegraph
To use this tool, you must visit www.telegra.ph. When going to this address, the user comes across an almost empty page with three simple lines: Title, Your name, Your story.
- The Title line is intended for writing the title of the article, which, together with the publication date, forms a link to the content. For example, the article “How to promote a website to the top 10,” published on April 5, will have the link: “http://telegra.ph/Kak-prodvinut-sajt-v-top-10-04-05.”
 The interface of the telegra.ph article creation tool is very simple
The interface of the telegra.ph article creation tool is very simple - The Your name item is optional. The author can indicate his real name, pseudonym, nickname, or leave the line completely blank so that no one can determine his identity. The ability to publish material while remaining incognito is quite interesting. But most writers are happy to indicate their authorship.
- Your story is a field for creating the main content. This also opens up the possibilities for text formatting, which were discussed above. The algorithm for creating an article is very simple and intuitive, so users should not have any difficulties writing it.
A unique link allows you to use the published material not only in Telegram, but also on other sites. However, the creator can make changes to the content at any time. However, this function only works if cookies are saved.
 To easily manage all articles, use the bot
To easily manage all articles, use the bot To create an article, a minimum of actions is required from the user. However, this ease has reverse side. Further editing can only be done on the same device and browser in which the text was first published. The developers foresaw this situation and created a special bot to manage publications. Let's list its functionality:
- Authorization in Telegraph from your Telegram account. By creating an entry in this way, you can log in to any other device and have editing access. When you log in for the first time on each device, the robot will offer to add all previously created posts to your account.
- Statistics of views of any telegraph post. This takes into account all transitions to the article, not only from Telegram, but also from any external resources. You can analyze not only your own publications, just send the bot the link you are interested in.
- You can set a permanent nickname and profile link so you don't have to specify them every time.
Telegraph - a real threat to traditional media?
Messengers, which inherently belong to the media sphere, are developing at a rapid pace, transforming into convenient platforms for posting useful information. The emergence of a service such as Telegraph has made it even easier to create a full-fledged business platform to attract the end user. Already, many brands are coming to the understanding that this type of communication is becoming increasingly relevant.
However, it is still premature to say that instant messengers in general and Telegraph in particular create direct competition with traditional media. Such services are defined by experts as an additional tool for generating Internet content, which can be a good help for the media, but at this stage of development is not able to completely absorb them.
 Online media are wary of competing platforms
Online media are wary of competing platforms Hacking at Google help
Alexander Antipov
Search engine Google system(www.google.com) provides many search options. All these features are an invaluable search tool for a user new to the Internet and at the same time an even more powerful weapon of invasion and destruction in the hands of people with evil intentions, including not only hackers, but also non-computer criminals and even terrorists.
(9475 views in 1 week)
Denis Barankov
denisNOSPAMixi.ru
Attention:This article is not a guide to action. This article was written for you, WEB server administrators, so that you will lose the false feeling that you are safe, and you will finally understand the insidiousness of this method of obtaining information and take up the task of protecting your site.
Introduction
For example, I found 1670 pages in 0.14 seconds!
2. Let's enter another line, for example:
inurl:"auth_user_file.txt"a little less, but this is already enough for free downloading and password guessing (using the same John The Ripper). Below I will give a number of more examples.
So, you need to realize that the Google search engine has visited most of the Internet sites and cached the information contained on them. This cached information allows you to obtain information about the site and the content of the site without directly connecting to the site, only by delving into the information that is stored inside Google. Moreover, if the information on the site is no longer available, then the information in the cache may still be preserved. All you need for this method is to know some Google keywords. This technique is called Google Hacking.
Information about Google Hacking first appeared on the Bugtruck mailing list 3 years ago. In 2001, this topic was raised by a French student. Here is a link to this letter http://www.cotse.com/mailing-lists/bugtraq/2001/Nov/0129.html. It provides the first examples of such queries:
1) Index of /admin
2) Index of /password
3) Index of /mail
4) Index of / +banques +filetype:xls (for france...)
5) Index of / +passwd
6) Index of / password.txt
This topic made waves in the English-reading part of the Internet quite recently: after the article by Johnny Long, published on May 7, 2004. For a more complete study of Google Hacking, I advise you to go to this author’s website http://johnny.ihackstuff.com. In this article I just want to bring you up to date.
Who can use this:
- Journalists, spies and all those people who like to poke their nose into other people's business can use this to search for incriminating evidence.
- Hackers looking for suitable targets for hacking.
How Google works.
To continue the conversation, let me remind you of some of the keywords used in Google queries.
Search using the + sign
Google excludes words it considers unimportant from searches. For example, question words, prepositions and articles in English language: for example are, of, where. In Russian Google language seems to consider all words important. If a word is excluded from the search, Google writes about it. In order for Google to start searching for pages with these words, you need to add a + sign without a space before the word. For example:
ace +of base
Search using the sign –
If Google finds a large number of pages from which it needs to exclude pages with a certain topic, then you can force Google to search only for pages that do not contain certain words. To do this, you need to indicate these words by placing a sign in front of each - without a space before the word. For example:
fishing - vodka
Search using ~
You may want to search not only the specified word, but also its synonyms. To do this, precede the word with the ~ symbol.
Finding an exact phrase using double quotes
Google searches on each page for all occurrences of the words that you wrote in the query string, and it does not care about the relative position of the words, as long as all the specified words are on the page at the same time (this is the default action). To find the exact phrase, you need to put it in quotes. For example:
"bookend"
In order to have at least one of the specified words, you need to specify the logical operation explicitly: OR. For example:
book safety OR protection
In addition, you can use the * sign in the search bar to indicate any word and. to represent any character.
Searching for words using additional operators
There are search operators that are specified in the search string in the format:
operator:search_term
Spaces next to the colon are not needed. If you insert a space after the colon, you will see an error message, and before it, Google will use them as a normal search string.
There are groups of additional search operators: languages - indicate in which language you want to see the result, date - limit the results for the past three, six or 12 months, occurrences - indicate where in the document you need to search for the line: everywhere, in the title, in the URL, domains - search on the specified site or, conversely, exclude it from the search; safe search - blocks sites containing the specified type of information and removes them from the search results pages.
However, some operators do not require an additional parameter, for example the request " cache:www.google.com" can be called as a full-fledged search string, and some keywords, on the contrary, require a search word, for example " site:www.google.com help". In the light of our topic, let's look at the following operators:
Operator |
Description |
Requires additional parameter? |
search only on the site specified in search_term |
||
search only in documents with type search_term |
||
find pages containing search_term in the title |
||
find pages containing all search_term words in the title |
||
find pages containing the word search_term in their address |
||
find pages containing all search_term words in their address |
Operator site: limits the search only to the specified site, and you can specify not only Domain name, but also an IP address. For example, enter:
Operator filetype: Limits the search to a specific file type. For example:
As of the publication date of the article, Google can search within 13 different file formats:
- Adobe Portable Document Format (pdf)
- Adobe PostScript (ps)
- Lotus 1-2-3 (wk1, wk2, wk3, wk4, wk5, wki, wks, wku)
- Lotus WordPro (lwp)
- MacWrite (mw)
- Microsoft Excel(xls)
- Microsoft PowerPoint (ppt)
- Microsoft Word(doc)
- Microsoft Works (wks, wps, wdb)
- Microsoft Write (wri)
- Rich Text Format (rtf)
- Shockwave Flash(swf)
- Text (ans, txt)
Operator link: shows all pages that point to the specified page.
It's probably always interesting to see how many places on the Internet know about you. Let's try:
Operator cache: shows the version of the site in Google cache what she looked like when Google latest visited this page once. Let’s take any frequently changing site and look:
Operator intitle: searches for the specified word in the page title. Operator allintitle: is an extension - it searches for all specified few words in the page title. Compare:
intitle:flight to Mars
intitle:flight intitle:on intitle:mars
allintitle:flight to mars
Operator inurl: forces Google to show all pages containing the specified string in the URL. allinurl operator: searches for all words in a URL. For example:
allinurl:acid acid_stat_alerts.php
This command is especially useful for those who don't have SNORT - at least they can see how it works on a real system.
Hacking Methods Using Google
So, we found out that using a combination of the above operators and keywords, anyone can collect the necessary information and search for vulnerabilities. These techniques are often called Google Hacking.
Site Map
You can use the site: operator to list all the links that Google has found on a site. Typically, pages that are dynamically created by scripts are not indexed using parameters, so some sites use ISAPI filters so that links are not in the form /article.asp?num=10&dst=5, and with slashes /article/abc/num/10/dst/5. This is done so that the site is generally indexed by search engines.
Let's try:
site:www.whitehouse.gov whitehouse
Google thinks that every page on a website contains the word whitehouse. This is what we use to get all the pages.
There is also a simplified version:
site:whitehouse.gov
And the best part is that the comrades from whitehouse.gov didn’t even know that we looked at the structure of their site and even looked at the cached pages that Google downloaded. This can be used to study the structure of sites and view content, remaining undetected for the time being.
View a list of files in directories
WEB servers can show lists of server directories instead of the usual ones HTML pages. This is usually done to encourage users to select and download certain files. However, in many cases, administrators have no intention of showing the contents of a directory. This occurs due to incorrect server configuration or lack of home page in the directory. As a result, the hacker has a chance to find something interesting in the directory and use it for his own purposes. To find all such pages, it is enough to note that they all contain the words: index of. But since the words index of contain not only such pages, we need to refine the query and take into account the keywords on the page itself, so queries like:
intitle:index.of parent directory
intitle:index.of name size
Since most directory listings are intentional, you may have a hard time finding misplaced listings the first time. But at least you can already use listings to determine the WEB server version, as described below.
Obtaining the WEB server version.
Knowing the WEB server version is always useful before launching any hacker attack. Again, thanks to Google, you can get this information without connecting to a server. If you look closely at the directory listing, you can see that the name of the WEB server and its version are displayed there.
Apache1.3.29 - ProXad Server at trf296.free.fr Port 80
An experienced administrator can change this information, but, as a rule, it is true. Thus, to obtain this information it is enough to send a request:
intitle:index.of server.at
To get information for a specific server, we clarify the request:
intitle:index.of server.at site:ibm.com
Or vice versa, we are looking for servers running a specific version of the server:
intitle:index.of Apache/2.0.40 Server at
This technique can be used by a hacker to find a victim. If, for example, he has an exploit for a certain version of the WEB server, then he can find it and try the existing exploit.
You can also get the server version by viewing the pages that are installed by default when installing the latest version of the WEB server. For example, to see the Apache 1.2.6 test page, just type
intitle:Test.Page.for.Apache it.worked!
Moreover, some OS During installation, they immediately install and launch the WEB server. However, some users are not even aware of this. Naturally, if you see that someone has not removed the default page, then it is logical to assume that the computer has not undergone any customization at all and is likely vulnerable to attack.
Try searching for IIS 5.0 pages
allintitle:Welcome to Windows 2000 Internet Services
In the case of IIS, you can determine not only the server version, but also Windows version and Service Pack.
Another way to determine the WEB server version is to search for manuals (help pages) and examples that may be installed on the site by default. Hackers have found quite a few ways to use these components to gain privileged access to a site. That is why you need to remove these components on the production site. Not to mention the fact that the presence of these components can be used to obtain information about the type of server and its version. For example, let's find the apache manual:
inurl:manual apache directives modules
Using Google as a CGI scanner.
CGI scanner or WEB scanner is a utility for searching for vulnerable scripts and programs on the victim’s server. These utilities must know what to look for, for this they have a whole list of vulnerable files, for example:
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/maillist.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgi
We can find each of these files using Google, additionally using the words index of or inurl with the file name in the search bar: we can find sites with vulnerable scripts, for example:
allinurl:/random_banner/index.cgi
Using additional knowledge, a hacker can exploit a script's vulnerability and use this vulnerability to force the script to emit any file stored on the server. For example, a password file.
How to protect yourself from Google hacking.
1. Do not post important data on the WEB server.
Even if you posted the data temporarily, you may forget about it or someone will have time to find and take this data before you erase it. Don't do this. There are many other ways to transfer data that protect it from theft.
2. Check your site.
Use the methods described to research your site. Check your site periodically for new methods that appear on the site http://johnny.ihackstuff.com. Remember that if you want to automate your actions, you need to get special permission from Google. If you read carefully http://www.google.com/terms_of_service.html, then you will see the phrase: You may not send automated queries of any sort to Google's system without express permission in advance from Google.
3. You may not need Google to index your site or part of it.
Google allows you to remove a link to your site or part of it from its database, as well as remove pages from the cache. In addition, you can prohibit the search for images on your site, prohibit short fragments of pages from being shown in search results. All possibilities for deleting a site are described on the page http://www.google.com/remove.html. To do this, you must confirm that you are really the owner of this site or insert tags into the page or
4. Use robots.txt
It is known that search engines look at the robots.txt file located at the root of the site and do not index those parts that are marked with the word Disallow. You can use this to prevent part of the site from being indexed. For example, to prevent the entire site from being indexed, create a robots.txt file containing two lines:
User-agent: *
Disallow: /
What else happens
So that life doesn’t seem like honey to you, I’ll say finally that there are sites that monitor those people who, using the methods outlined above, look for holes in scripts and WEB servers. An example of such a page is
Application.
A little sweet. Try some of the following for yourself:
1. #mysql dump filetype:sql - search for database dumps mySQL data
2. Host Vulnerability Summary Report - will show you what vulnerabilities other people have found
3. phpMyAdmin running on inurl:main.php - this will force control to be closed through the phpmyadmin panel
4. not for distribution confidential
5. Request Details Control Tree Server Variables
6. Running in Child mode
7. This report was generated by WebLog
8. intitle:index.of cgiirc.config
9. filetype:conf inurl:firewall -intitle:cvs – maybe someone needs firewall configuration files? :)
10. intitle:index.of finances.xls – hmm....
11. intitle:Index of dbconvert.exe chats – icq chat logs
12.intext:Tobias Oetiker traffic analysis
13. intitle:Usage Statistics for Generated by Webalizer
14. intitle:statistics of advanced web statistics
15. intitle:index.of ws_ftp.ini – ws ftp config
16. inurl:ipsec.secrets holds shared secrets - secret key - good find
17. inurl:main.php Welcome to phpMyAdmin
18. inurl:server-info Apache Server Information
19. site:edu admin grades
20. ORA-00921: unexpected end of SQL command – getting paths
21. intitle:index.of trillian.ini
22. intitle:Index of pwd.db
23.intitle:index.of people.lst
24. intitle:index.of master.passwd
25.inurl:passlist.txt
26. intitle:Index of .mysql_history
27. intitle:index of intext:globals.inc
28. intitle:index.of administrators.pwd
29. intitle:Index.of etc shadow
30.intitle:index.ofsecring.pgp
31. inurl:config.php dbuname dbpass
32. inurl:perform filetype:ini
Training center "Informzashchita" http://www.itsecurity.ru - a leading specialized center in the field of training information security(License of the Moscow Committee of Education No. 015470, State accreditation No. 004251). The only authorized training center for companies Internet Security Systems and Clearswift in Russia and the CIS countries. Microsoft authorized training center (Security specialization). The training programs are coordinated with the State Technical Commission of Russia, the FSB (FAPSI). Certificates of training and state documents on advanced training.
SoftKey is a unique service for buyers, developers, dealers and affiliate partners. Moreover, this is one of the best online stores Software in Russia, Ukraine, Kazakhstan, which offers customers a wide range, many payment methods, prompt (often instant) order processing, tracking the order process in a personal section, various discounts from the store and software manufacturers.
How to search correctly using google.com
Everyone probably knows how to use this search engine, like Google =) But not everyone knows that if you correctly compose a search query using special constructions, you can achieve the results of what you are looking for much more efficiently and quickly =) In this article I will try to show what and how you need to do in order search correctly
Google supports several advanced search operators that have special meaning when searching on google.com. Typically, these operators change the search, or even tell Google to do it completely Various types search. For example, the design link: is a special operator, and the request link:www.google.com will not give you a normal search, but will instead find all web pages that have links to google.com.
alternative request types
cache: If you include other words in your query, Google will highlight those included words within the cached document.
For example, cache:www.web site will show the cached content with the word "web" highlighted.
link: The search query above will show web pages that contain links to the specified query.
For example: link:www.site will display all pages that have a link to http://www.site
related: Displays web pages that are “related” to the specified web page.
For example, related: www.google.com will list web pages that are similar to Google's home page.
info: Query Information: will present some of the information Google has about the web page you are requesting.
For example, info:website will show information about our forum =) (Armada - Adult Webmasters Forum).
Other information requests
define: The define: query will provide a definition of the words you enter after it, collected from various online sources. The definition will be for the entire phrase entered (that is, it will include all words in the exact query).
stocks: If you start a query with stocks: Google will process the rest of the query terms as stock symbols, and link to a page showing ready-made information for these symbols.
For example, stocks:Intel yahoo will show information about Intel and Yahoo. (Note that you should type breaking news symbols, not the company name)
Query Modifiers
site: If you include site: in your query, Google will limit the results to those websites that it finds in that domain.
You can also search by individual zones, such as ru, org, com, etc ( site:com site:ru)
allintitle: If you run a query with allintitle:, Google will limit the results to all the query words in the title.
For example, allintitle: google search will return all Google pages by search such as images, Blog, etc
intitle: If you include intitle: in your query, Google will limit the results to documents containing that word in the title.
For example, intitle:Business
allinurl: If you run a query with allinurl: Google will limit the results to all query words in the URL.
For example, allinurl: google search will return documents with google and search in the title. Also, as an option, you can separate words with a slash (/) then words on both sides of the slash will be searched within the same page: Example allinurl: foo/bar
inurl: If you include inurl: in your query, Google will limit the results to documents containing that word in the URL.
For example, Animation inurl:site
intext: searches only the specified word in the text of the page, ignoring the title and texts of links, and other things not related to. There is also a derivative of this modifier - allintext: those. further, all words in the query will be searched only in the text, which can also be important, ignoring frequently used words in links
For example, intext:forum
daterange: searches in a time frame (daterange:2452389-2452389), dates for times are indicated in Julian format.
Well, and all sorts of interesting examples of queries
Examples of writing queries for Google. For spammers
Inurl:control.guest?a=sign
Site:books.dreambook.com “Homepage URL” “Sign my” inurl:sign
Site:www.freegb.net Homepage
Inurl:sign.asp “Character Count”
“Message:” inurl:sign.cfm “Sender:”
Inurl:register.php “User Registration” “Website”
Inurl:edu/guestbook “Sign the Guestbook”
Inurl:post “Post Comment” “URL”
Inurl:/archives/ “Comments:” “Remember info?”
“Script and Guestbook Created by:” “URL:” “Comments:”
Inurl:?action=add “phpBook” “URL”
Intitle:"Submit New Story"
Magazines
Inurl:www.livejournal.com/users/ mode=reply
Inurl greatestjournal.com/ mode=reply
Inurl:fastbb.ru/re.pl?
Inurl:fastbb.ru /re.pl? "Guest book"
Blogs
Inurl:blogger.com/comment.g?”postID””anonymous”
Inurl:typepad.com/ “Post a comment” “Remember personal info?”
Inurl:greatestjournal.com/community/ “Post comment” “addresses of anonymous posters”
“Post comment” “addresses of anonymous posters” -
Intitle:"Post comment"
Inurl:pirillo.com “Post comment”
Forums
Inurl:gate.html?”name=Forums” “mode=reply”
Inurl:”forum/posting.php?mode=reply”
Inurl:"mes.php?"
Inurl:”members.html”
Inurl:forum/memberlist.php?”
The Stories function, or “Stories” in Russian localization, allows you to create photos and 10-second videos with overlay of text, emoji and handwritten notes. Key Feature The thing about such posts is that, unlike regular publications in your feed, they do not live forever and are deleted after exactly 24 hours.
Why is it necessary?
The official Instagram description says that new feature not really needed for exchange important information about everyday life.
How to use it
At its core, the innovation is very similar to and works approximately the same, but with minor differences. Despite the fact that the opportunities Instagram Stories not so many and they are all very simple; not all users can figure them out right away.
View stories
All available stories are displayed at the top of the feed in the form of circles with user avatars and are hidden while scrolling. New stories appear as they are published, and a day later they disappear without a trace. In this case, stories are sorted not in chronological order, but by the number of playback cycles and comments.

To view, you just need to tap on the circle. A photo or video will open and display for 10 seconds. Tap and hold pauses the video.
At the top, next to the username, the time of publication is shown. If the people you follow have other stories, the next ones will be shown immediately after the first one. You can switch between them by swiping left and right.


Stories that you have already viewed do not disappear from the menu, but are greyed out. They can be opened again until they are deleted after a day.
You can comment on stories only using messages that are sent to Direct and are visible only to the author, and not to all subscribers. Whether this is a bug or a feature is unknown.
Creating stories
Clicking on the plus sign at the top of the feed and swiping from the edge of the screen to the right opens the menu for recording a new story. Everything is simple here: tap on the record button - we get a photo, hold it down - we shoot a video.
Shooting or uploading


You can switch the front and rear cameras or turn on the flash. It is also easy to select a media file from those that were shot over the past 24 hours: this is done by swiping down. All photos from the gallery go here, including time-lapses and branded boomerangs.
Treatment
When the photo or video is ready, you can publish it after processing it. For both photos and videos, the tools are the same: filters, text and emoji, drawings.


Filters are switched in a circle with simple swipes from the edge of the screen. There are six of them in total, including a rainbow gradient like on the Instagram icon.
The added text can be enlarged or reduced, or moved around the photo. But, unfortunately, you cannot leave more than one comment. Emoji are also inserted through the text, so if you want to cover your face with an emoticon, you have to choose.


Drawing has a little more options. We have a palette and three brushes at our disposal: regular, marker and with a “neon” stroke. You can draw with everyone at once, and a bad stroke can be undone.
Are you satisfied with the result? Click the checkmark button and your video will be available to subscribers. It can be saved to the gallery both before and after.
Privacy settings, statistics


The settings and statistics screen is called up by swiping up while viewing a story. From here, the story can be saved to the gallery, deleted, or published in the main feed, turning it into a regular post. The list of spectators is displayed below. You can hide the story from any of them by clicking on the cross next to the name.


The settings, which are hidden behind the gear icon, allow you to choose who can respond to your stories and hide the story from certain subscribers. In this case, the privacy settings are remembered and applied to all subsequent publications.
How to live with it
Fine. Yes, many were hostile to Stories due to the similarity to Snapchat and the unresolved problems of Instagram, which developers should focus on. But I think the innovation is useful.
The problem of a cluttered feed, when you have to unfollow friends who post literally every step they take, has existed for a long time, and no clear solution has ever been invented. Stories can be considered the first step towards this. Over time, people should get used to the culture of behavior offered by , and start posting only really important and noteworthy content to their feed. Everything else should go into Stories. It's true?
Obtaining private data does not always mean hacking - sometimes it is published in public access. Knowledge Google settings and a little ingenuity will allow you to find a lot of interesting things - from credit card numbers to FBI documents.
WARNING
All information is provided for informational purposes only. Neither the editors nor the author are responsible for any possible harm caused by the materials of this article.Today, everything is connected to the Internet, with little concern for restricting access. Therefore, many private data become the prey of search engines. Spider robots are no longer limited to web pages, but index all content available on the Internet and constantly add non-public information to their databases. Finding out these secrets is easy - you just need to know how to ask about them.
Looking for files
In capable hands, Google will quickly find everything that is not found on the Internet, for example, personal information and files for official use. They are often hidden like a key under a rug: there are no real access restrictions, the data simply lies on the back of the site, where no links lead. The standard Google web interface provides only basic advanced search settings, but even these will be sufficient.
You can limit your Google search to a specific type of file using two operators: filetype and ext . The first specifies the format that the search engine determined from the file title, the second specifies the file extension, regardless of its internal content. When searching in both cases, you only need to specify the extension. Initially, the ext operator was convenient to use in cases where the file did not have specific format characteristics (for example, to search for ini and cfg configuration files, which could contain anything). Now Google's algorithms have changed, and there is no visible difference between operators - in most cases the results are the same.

Filtering the results
By default, Google searches for words and, in general, any entered characters in all files on indexed pages. You can limit your search by domain top level, a specific site or at the location of the desired sequence in the files themselves. For the first two options, use the site operator, followed by the name of the domain or selected site. In the third case, a whole set of operators allows you to search for information in service fields and metadata. For example, allinurl will find the given one in the body of the links themselves, allinanchor - in the text equipped with the tag , allintitle - in page titles, allintext - in the body of pages.
For each operator there is a lightweight version with a shorter name (without the prefix all). The difference is that allinurl will find links with all words, and inurl will only find links with the first of them. The second and subsequent words from the query can appear anywhere on web pages. The inurl operator also differs from another operator with a similar meaning - site. The first also allows you to find any sequence of characters in a link to the searched document (for example, /cgi-bin/), which is widely used to find components with known vulnerabilities.
Let's try it in practice. We take the allintext filter and make the request produce a list of numbers and verification codes of credit cards that will expire only in two years (or when their owners get tired of feeding everyone).
Allintext: card number expiration date /2017 cvv 
When you read in the news that a young hacker “hacked into the servers” of the Pentagon or NASA, stealing classified information, in most cases we are talking about just such a basic technique of using Google. Suppose we are interested in a list of NASA employees and their contact information. Surely such a list is available in electronic form. For convenience or due to oversight, it may also be on the organization’s website itself. It is logical that in this case there will be no links to it, since it is intended for internal use. What words can be in such a file? At a minimum - the “address” field. Testing all these assumptions is easy.

Inurl:nasa.gov filetype:xlsx "address"

We use bureaucracy
Finds like this are a nice touch. A truly solid catch is provided by a more detailed knowledge of Google's operators for webmasters, the Network itself, and the peculiarities of the structure of what is being sought. Knowing the details, you can easily filter the results and refine the properties of the necessary files in order to get truly valuable data in the rest. It's funny that bureaucracy comes to the rescue here. It produces standard formulations that are convenient for searching for secret information accidentally leaked onto the Internet.
For example, the Distribution statement stamp, required by the US Department of Defense, means standardized restrictions on the distribution of a document. The letter A denotes public releases in which there is nothing secret; B - intended only for internal use, C - strictly confidential, and so on until F. The letter X stands out separately, which marks particularly valuable information representing a state secret of the highest level. Let those who are supposed to do this on duty search for such documents, and we will limit ourselves to files with the letter C. According to DoDI directive 5230.24, this marking is assigned to documents containing a description of critical technologies that fall under export control. You can find such carefully protected information on sites in the top-level domain.mil, allocated for the US Army.
"DISTRIBUTION STATEMENT C" inurl:navy.mil 
It is very convenient that the .mil domain contains only sites from the US Department of Defense and its contract organizations. Search results with a domain restriction are exceptionally clean, and the titles speak for themselves. Searching for Russian secrets in this way is practically useless: chaos reigns in domains.ru and.rf, and the names of many weapons systems sound like botanical ones (PP “Kiparis”, self-propelled guns “Akatsia”) or even fabulous (TOS “Buratino”).

By carefully studying any document from a site in the .mil domain, you can see other markers to refine your search. For example, a reference to the export restrictions “Sec 2751”, which is also convenient for searching for interesting technical information. From time to time it is removed from official sites where it once appeared, so if you cannot follow an interesting link in the search results, use Google’s cache (cache operator) or the Internet Archive site.
Climbing into the clouds
In addition to accidentally declassified government documents, links to personal files from Dropbox and other data storage services that create “private” links to publicly published data occasionally pop up in Google's cache. It’s even worse with alternative and homemade services. For example, the following query finds data for all Verizon customers who have an FTP server installed and actively using their router.
Allinurl:ftp:// verizon.net
There are now more than forty thousand such smart people, and in the spring of 2015 there were many more of them. Instead of Verizon.net, you can substitute the name of any well-known provider, and the more famous it is, the larger the catch can be. Through the built-in FTP server, you can see files on an external storage device connected to the router. Usually this is a NAS for remote work, a personal cloud, or some kind of peer-to-peer file downloading. All contents of such media are indexed by Google and other search engines, so you can access files stored on external drives via a direct link.

Looking at the configs
Before the widespread migration to the cloud, simple FTP servers ruled as remote storage, which also had a lot of vulnerabilities. Many of them are still relevant today. For example, the popular WS_FTP Professional program stores configuration data, user accounts and passwords in the ws_ftp.ini file. It is easy to find and read, since all records are saved in text format, and passwords are encrypted with the Triple DES algorithm after minimal obfuscation. In most versions, simply discarding the first byte is sufficient.

It is easy to decrypt such passwords using the WS_FTP Password Decryptor utility or a free web service.

When talking about hacking an arbitrary website, they usually mean obtaining a password from logs and backups of configuration files of CMS or e-commerce applications. If you know them typical structure, you can easily specify keywords. Lines like those found in ws_ftp.ini are extremely common. For example, in Drupal and PrestaShop there is always a user identifier (UID) and a corresponding password (pwd), and all information is stored in files with the .inc extension. You can search for them as follows:
"pwd=" "UID=" ext:inc
Revealing DBMS passwords
In the configuration files of SQL servers, names and addresses Email users are stored in clear text, and instead of passwords, their MD5 hashes are recorded. Strictly speaking, it is impossible to decrypt them, but you can find a match among the known hash-password pairs.

There are still DBMSs that do not even use password hashing. The configuration files of any of them can simply be viewed in the browser.
Intext:DB_PASSWORD filetype:env 
Since appearing on Windows servers The place of configuration files was partially taken by the registry. You can search through its branches in exactly the same way, using reg as the file type. For example, like this:
Filetype:reg HKEY_CURRENT_USER "Password"= 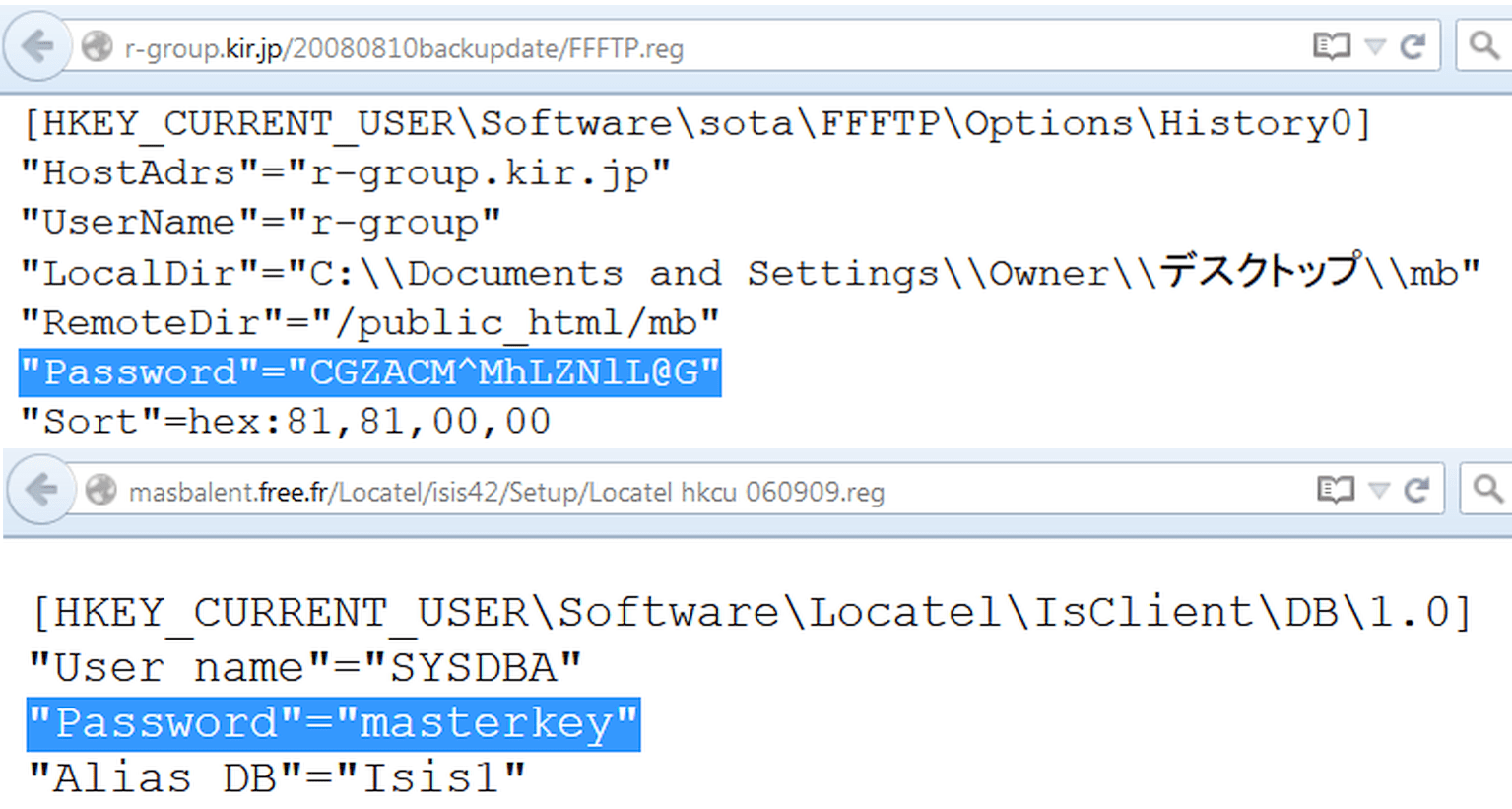
Let's not forget the obvious
Sometimes it is possible to get to classified information using data that was accidentally opened and came to the attention of Google. Perfect option- find a list of passwords in some common format. Store account information in text file, Word document or an Excel spreadsheet can only be done by desperate people, but there are always enough of them.
Filetype:xls inurl:password 
On the one hand, there are a lot of means to prevent such incidents. It is necessary to specify adequate access rights in htaccess, patch the CMS, not use left-handed scripts and close other holes. There is also a file with a list of robots.txt exceptions that prohibits search engines from indexing the files and directories specified in it. On the other hand, if the structure of robots.txt on some server differs from the standard one, then it immediately becomes clear what they are trying to hide on it.

The list of directories and files on any site is preceded by the standard index of. Since for service purposes it must appear in the title, it makes sense to limit its search to the intitle operator. Interesting things are in the /admin/, /personal/, /etc/ and even /secret/ directories.

Stay tuned for updates
Relevance is extremely important here: old vulnerabilities are closed very slowly, but Google and its search results are constantly changing. There is even a difference between a “last second” filter (&tbs=qdr:s at the end of the request URL) and a “real time” filter (&tbs=qdr:1).
Date time interval last update Google also indicates the file implicitly. Through the graphical web interface, you can select one of the standard periods (hour, day, week, etc.) or set a date range, but this method is not suitable for automation.
From the look of the address bar, you can only guess about a way to limit the output of results using the &tbs=qdr: construction. The letter y after it sets the limit of one year (&tbs=qdr:y), m shows the results for the last month, w - for the week, d - for the past day, h - for the last hour, n - for the minute, and s - for give me a sec. The most recent results that Google has just made known are found using the filter &tbs=qdr:1 .
If you need to write a clever script, it will be useful to know that the date range is set in Google in Julian format using the daterange operator. For example, this is how you can find a list PDF documents with the word confidential, uploaded from January 1 to July 1, 2015.
Confidential filetype:pdf daterange:2457024-2457205
The range is indicated in Julian date format without taking into account the fractional part. Translating them manually from the Gregorian calendar is inconvenient. It's easier to use a date converter.
Targeting and filtering again
In addition to specifying additional operators in search query they can be sent directly in the body of the link. For example, the filetype:pdf specification corresponds to the construction as_filetype=pdf . This makes it convenient to ask any clarifications. Let's say that the output of results only from the Republic of Honduras is specified by adding the construction cr=countryHN to the search URL, and only from the city of Bobruisk - gcs=Bobruisk. You can find a complete list in the developer section.
Google's automation tools are designed to make life easier, but they often add problems. For example, the user’s city is determined by the user’s IP through WHOIS. Based on this information, Google not only balances the load between servers, but also changes the search results. Depending on the region, for the same request, different results will appear on the first page, and some of them may be completely hidden. The two-letter code after the gl=country directive will help you feel like a cosmopolitan and search for information from any country. For example, the code of the Netherlands is NL, but the Vatican and North Korea do not have their own code in Google.
Often, search results end up cluttered even after using several advanced filters. In this case, it is easy to clarify the request by adding several exception words to it (a minus sign is placed in front of each of them). For example, banking, names and tutorial are often used with the word Personal. Therefore, cleaner search results will be shown not by a textbook example of a query, but by a refined one:
Intitle:"Index of /Personal/" -names -tutorial -banking
One last example
A sophisticated hacker is distinguished by the fact that he provides himself with everything he needs on his own. For example, VPN is a convenient thing, but either expensive, or temporary and with restrictions. Signing up for a subscription for yourself is too expensive. It's good that there are group subscriptions, and with the help of Google it's easy to become part of a group. To do this, just find the Cisco VPN configuration file, which has a rather non-standard PCF extension and a recognizable path: Program Files\Cisco Systems\VPN Client\Profiles. One request and you join, for example, the friendly team of the University of Bonn.
Filetype:pcf vpn OR Group 
INFO
Google finds password configuration files, but many of them are encrypted or replaced with hashes. If you see strings of a fixed length, then immediately look for a decryption service.Passwords are stored encrypted, but Maurice Massard has already written a program to decrypt them and provides it for free through thecampusgeeks.com.
Google does hundreds of things different types attacks and penetration tests. There are many options, affecting popular programs, major database formats, numerous vulnerabilities of PHP, clouds, and so on. Knowing exactly what you're looking for will make it much easier to find the information you need (especially information you didn't intend to make public). Shodan is not the only one that feeds with interesting ideas, but every database of indexed network resources!



